OAM(Open Application Model) 是阿里巴巴(主要负责人孙建波)和微软(主要负责人Matt Butcher)共同开源的云原生应用规范模型,同时开源了基于OAM的实现Rudr(RUST语言编写). 从宣布开源到现在已经有半年多了.
可能大部分人已经开始了解OAM, 这篇文章从基础出发, 给大家介绍OAM的诞生背景和解决的问题, 以及它在云原生生态中作用,和一些简单的使用OAM部署应用的实践.
核心观点
OAM的本质是根据软件设计的"兴趣点分离或者叫组织结构的作用分离"原则对负责的DevOps流程的高度抽象和封装, 这还是按照"康威定律"的理念设计.OAM仅定义云原生应用的规范,目前推出的Rudr可以理解为是OAM 规范的kubernetes 实现(解释器, 实验版本),将云原生应用定义翻译程Kunernetes的资源对象.OAM与Crossplan合作,就Kuernetes式以API为中心的应用定义发扬光大, 并深度参与CNCF SIG App Delivery,以共同定义云原生应用标准.
康威定律(Conway’s Law)是马尔文·康威(Melvin Conway)1967年提出的: “设计系统的架构受制于产生这些设计的组织的沟通结构。
OAM 简介
OAM 全称是 Open Application Model, 本质就是一种模型, 这种模型旨在定义了云原生应用的标准.
- 开放(Open): 支持异构的平台, 容器运行时, 调度系统, 云供应商, 硬件配置等,总之与底层无关.
- 应用(Appplication): 云原生应用
- 模型(Model): 定义标准, 以使其与底层平台无关.
CNCF中也有几个定义标准的开源项目, 其中有的项目已经毕业.
- SMI(Service Mesh Interface): 服务网格接口
- Cloud Events: Serviceless中的事件标准
- TUF: 更新框架标准
- SPIFF: 身份安全标准
这其中唯独没有应用标准的定义, CNCF SIG App delivery 就是要做这个. 制订标准, 就要对不同平台和场景的逻辑做出更高级别的抽象, 这样才能屏蔽底层差异.
这其中是从管理大量的crd资源中汲取的经验. 业务和研发的沟通成本,比如YAML配置中很多字段是开发人员不需要关心的.
在应用程序开发和部署方面,我们认为区分开发人员负责的部分和运维人员负责的部分非常重要.
OAM试图通过根据负责构建和运行应用程序以及运维基础架构设施的角色对应用进行建模来解决这个问题.
OAM 主要有三个特点:
- 开发和运维关注点分离:开发者关注业务逻辑,运维人员关注运维能力,让不同角色更专注于领域知识和能力
- 平台无关与高可扩展:应用定义与平台实现解耦,应用描述支持跨平台实现和可扩展性;
- 模块化应用部署和运维特征:应用部署和运维能力可以描述成高层抽象模块,开发和运维可以自由组合和支持模块化实现
角色分类
OAM 将应用相关的人员划分为 3 个角色:
- 应用开发:关注应用代码开发和运行配置,是应用代码的领域专家,应用开发完成后打包(比如镜像)交给应用运维
- 应用运维:关注配置和运行应用实例的生命周期,比如灰度发布、监控、报警等操作,是应用运维专家;
- 平台运维:关注应用运行平台的能力和稳定性,是底层(比如 Kubernetes 运维/优化,OS 等)的领域专家
OAM 核心概念
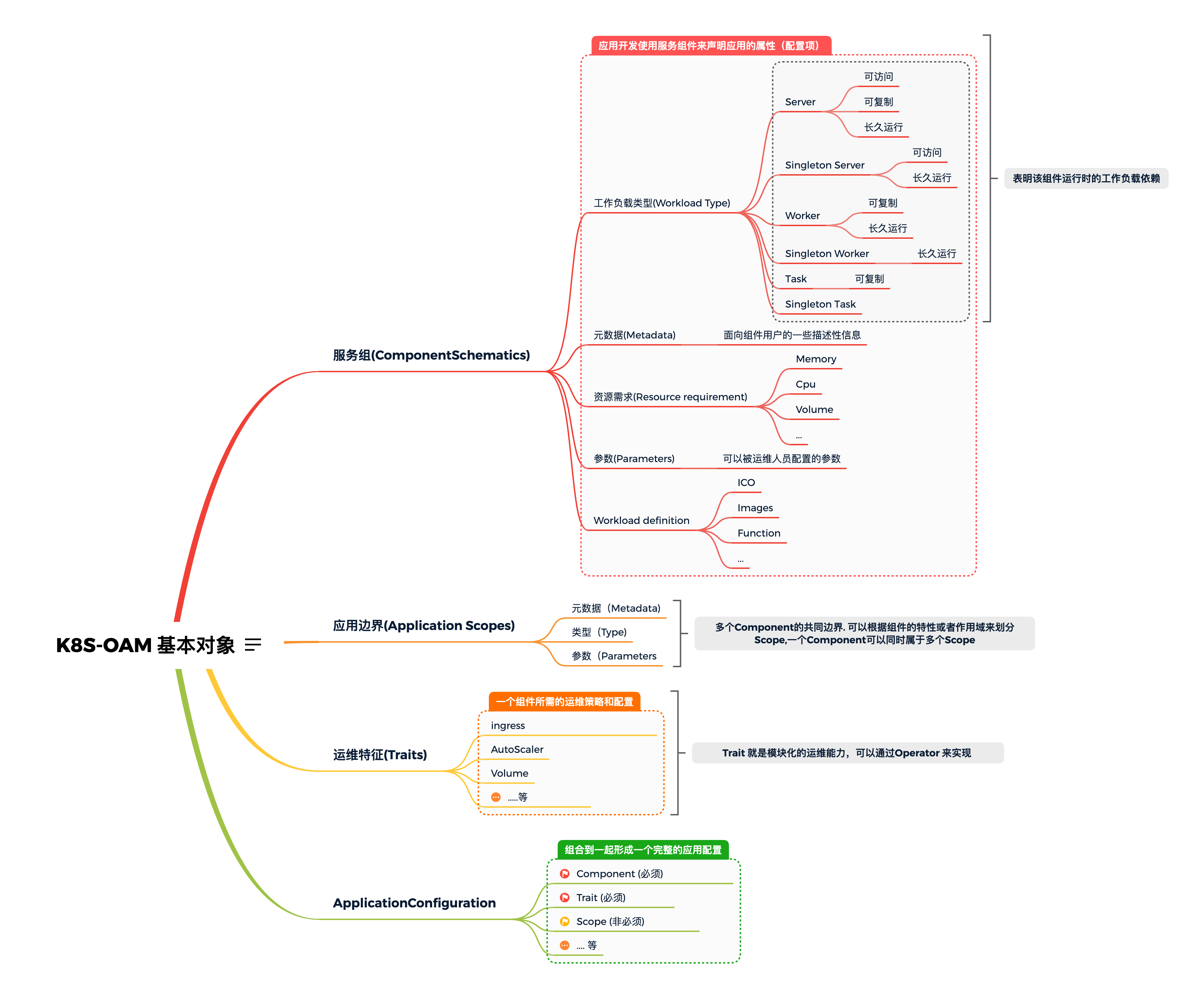
OAM 包含以下核心概念:
-
服务组件(Component Schematics) 应用开发使用服务组件来声明应用的属性(配置项),运维人员定义这些属性之后就能按照组件声明得到运行的组件实例,组件声明包含以下信息:
- 工作负载类型(Workload type):表明该组件运行时的工作负载依赖;
- 元数据(Metadata):面向组件用户的一些描述性信息
- 资源需求(Resource requirements):组件运行的最小资源需求,比如最小内存,CPU 和文件挂载需求
- 参数(Parameters):可以被运维人员配置的参数;
- 工作负载定义(Workload definition):工作负载运行的一些定义,比如可运行包定义(ICO images, Function等)
-
应用边界(Application Scopes) 运维人员使用应用边界将组件组成松耦合的应用,可以赋予这组组件一些共用的属性和依赖,应用边界声明包含以下信息:
- 元数据(Metadata):面向应用边界用户的一些描述性信息。
- 类型(Type):边界类型,不同类型提供不同的能力
- 参数(Parameters):可以被运维人员配置的参数
-
运维特征(Traits) 运维人员使用运维特征赋予组件实例特定的运维能力,比如自动扩缩容,一个 Trait 可能仅限特定的工作负载类型,它们代表了系统运维方面的特性,而不是开发的特性,比如开发者知道自己的组件是否可以扩缩容,但是运维可以决定是手动扩缩容还是自动扩缩容,特征声明包含以下信息
- 元数据(Metadata):面向特征用户的一些描述性信息
- 适用工作负载列表(Applies-to list):该特征可以应用的工作负载列表;
- 属性(Properties):可以被运维人员配置的属性。
-
工作负载类型和配置(Workload types and configurations 描述特定工作负载的底层运行时,平台需要能够提供对应工作负载的运行时,工作负载声明包含以下信息:
- 元数据(Metadata):面向工作负载用户的一些描述性信息;
- 工作负载设置(Workload Setting):可以被运维人员配置的设置
-
应用配置(Application configuration 运维人员使用应用配置将组件、特征和应用边界的组合在一起实例化部署,应用配置声明包含以下信息:
- 元数据(Metadata):面向应用配置用户的一些描述性信息;
- 参数覆盖(Parameter overrides):可以理解为变量定义,可以被组件、特征、应用边界的参数引用
- 组件设置(Component):构成应用的全部组件都在这里设置
- 绑定组件的运维特征配置(Trait Configuration):绑定的特征列表及其参数
OAM 认为:
一个云原生应用由一组相互关联但又离散独立的组件构成,这些组件实例化在合适的运行时上,由配置来控制行为并共同协作提供统一的功能。
更加具体的说
一个 Application 由一组 Components 构成,每个 Component 的运行时由 Workload 描述,每个 Component 可以施加 Traits 来获取额外的运维能力,同时我们可以使用 Application scopes 将 Components 划分到 1 或者多个应用边界中,便于统一做配置、限制、管理。

OAM工作原理
OAM的工作原理如下图所示, OAM Spec定义了云原生应用的规范(使用一些CRD定义), Rudr可以看做是OAM规范的解释器, 将应用定义翻译为Kubernetes中的资源对象.
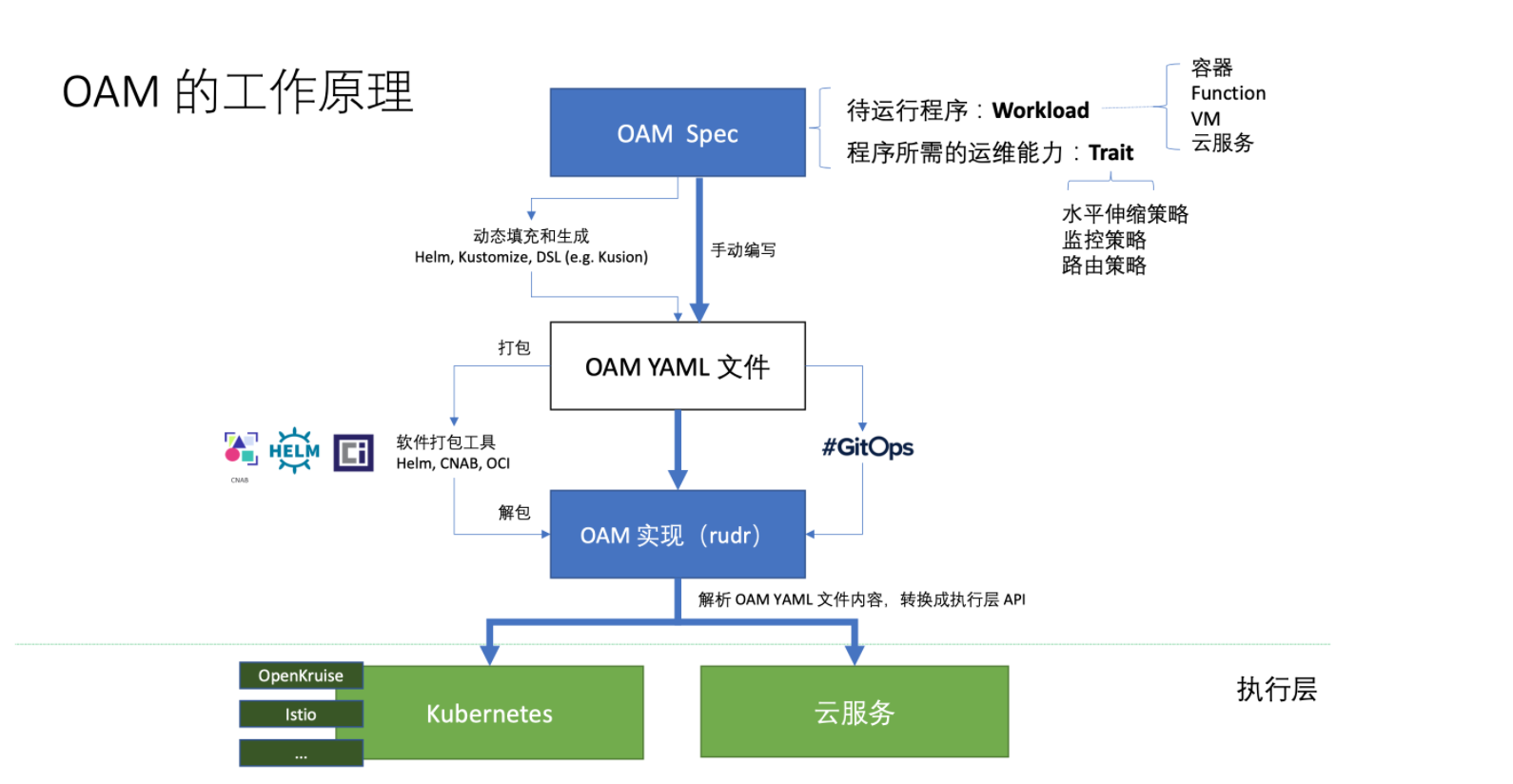
可以将上图分为三个层次:
- 汇编层: 即人工或者使用工具来根据 OAM 规范定义汇编出一个云原生应用的定义,其中包含了该应用的工作负载和运维能力配置
- 转义层: 汇编好的文件将打包为 YAML 文件,由 Rudr 或其他 OAM 的实现将其转义为 Kubernetes 或其他云服务(例如 Istio)上可运行的资源对象
- 执行层: 执行经过转义好的云平台上的资源对象并执行资源配置
Rudr (OAM的实现)
Rudr 是对 OAM v1alpha1在Kubernetes环境下对实现, OAM 正在与Crossplane合作.
安装Rudr
这样依赖以下组件:
- kubectl
- helm3
- Kubernetes 1.15+
安装Rudr 和 需要的 trait
git clone https://github.com/oam-dev/rudr.git
cd rudr
# 创建一个名为oam的namespace
kubectl create namespace oam
# 安装Rudr
helm install rudr ./charts/rudr --wait -n oam
# 要使用 ingress trait,推荐安装 Nginx ingress
helm repo add stable https://kubernetes-charts.storage.googleapis.com/
helm install nginx-ingress stable/nginx-ingress
# 要使用 autoscaler trait,安装 HorizontalPodAutoscaler
helm repo add kedacore https://kedacore.github.io/charts
helm repo update
helm install keda kedacore/keda -n oam
场景 1
部署一个python web服务, 通过nginx(这里使用ingress)来暴露入口.
首先先定义一个component(这个组件一般是开发者关心的) helloworld-python-component.yaml
apiVersion: core.oam.dev/v1alpha1
kind: ComponentSchematic
metadata:
name: helloworld-python-v1
spec:
workloadType: core.oam.dev/v1alpha1.Server
containers:
- name: foo
image: oamdev/helloworld-python:v1
env:
- name: TARGET
fromParam: target
- name: PORT
fromParam: port
ports:
- protocol: TCP
containerPort: 9999
name: http
resources:
cpu:
required: 0.1
memory:
required: "128"
parameters:
- name: target
type: string
default: World
- name: port
type: string
default: "9999"
部署这个component
kubectl apply -f helloworld-python-component.yaml
上面的资源清单文件, 首先我们需要关注的是workloadType 字段,用来表示工作负载, 类型是Server(可访问, 可复制, 长久运行). 上面的yaml文件只是定义了一个名称为helloworld-python-v1的ComponentSchematic,但是ComponentSchematic 仅仅是定义了一个组件而已, 还无法直接创建pod,还需要创建一个ApplicationConfiguration将其与Trait绑定才可以创建应用的pod.
创建应用配置(ApplicationConfiguration)
在部署了 ComponentSchematic 之后我们还需要创建一个 ApplicationConfiguration 将其与Trait资源绑定才可以创建应用.
我们可以先查看当前Rudr中已经存在了的Trait, 使用下面的命令查看:
➜ ~ kubectl get trait
NAME AGE
auto-scaler 6h24m
empty 6h24m
ingress 6h24m
manual-scaler 6h24m
volume-mounter 6h24m
定义ApplicationConfiguration first-app-config.yaml 内容如下:
apiVersion: core.oam.dev/v1alpha1
kind: ApplicationConfiguration
metadata:
name: first-app
spec:
components:
- componentName: helloworld-python-v1
instanceName: first-app-helloworld-python-v1
parameterValues:
- name: target
value: Rudr
- name: port
value: '9999'
traits:
- name: ingress
properties:
hostname: example.com
path: /
servicePort: 9999
这是一个应用程序配置的示例,该应用程序由单个组件组成,该组件的包含一个ingress的trait, 域名为example.com,服务端口为9999.
安装这个ApplicationConfiguration:
kubectl apply -f first-app-config.yaml
我们查看下我们所部署的 ApplicationConfiguration:
➜ ~ kubectl get applicationconfigurations
NAME AGE
first-app 4h16m
我们测试下访问:
export POD_NAME=$(kubectl get pods -l "oam.dev/instance-name=first-app-helloworld-python-v1,app.kubernetes.io/name=first-app" -o jsonpath="{.items[0].metadata.name}")
kubectl port-forward $POD_NAME 9999:9999
➜ curl -i http://127.0.0.1:9999
HTTP/1.1 200 OK
Server: gunicorn/19.9.0
Date: Fri, 08 May 2020 10:27:09 GMT
Connection: close
Content-Type: text/html; charset=utf-8
Content-Length: 12
Hello Rudr!
场景 2
我们来声明一个资源清单, 我们这里的应用是一个简单的TODO应用, 基于后端存储MongoDB的Express框架实现, 所以我们这里声明一个MongoDB组件和Web应用组件,将他们分别称为后端和前端组件(components.yaml):
apiVersion: core.oam.dev/v1alpha1
kind: ComponentSchematic
metadata:
name: backend
annotations:
version: "1.0.0"
description: Mongodb Backend
spec:
workloadType: core.oam.dev/v1alpha1.SingletonServer
containers:
- name: backend
ports:
- containerPort: 27017
name: mongo
image: mongo
---
apiVersion: core.oam.dev/v1alpha1
kind: ComponentSchematic
metadata:
name: frontend
annotations:
version: "1.0.0"
description: Todo Web Frontend
spec:
workloadType: core.oam.dev/v1alpha1.Server
parameters:
- name: database
type: string
required: false
containers:
- name: frontend
ports:
- containerPort: 3000
name: http
image: cnych/todo:v1
env:
- name: DB
value: db
fromParam: database
上面的资源清单文件workloadType 类型都是Server, 但是MongoDB 只需要运行一个Pod即可,因为是有状态的,多个副本需要很复杂的集群配置,所以为了简单我们这里始终运行一个Pod副本,所以这里使用的是一个 SingletonServer,表示单实例的服务. 我们的 Node 服务会优先检查环境变量 DB,如果该变量值为空,则将使用使用字符串 db 作为默认的值,上面资源清单中我们在 web 应用程序中声明了 parameters 部分,这个部分其实一般是开发定义的,但是运行运维后续来进行覆盖,所以这里的用途就是告诉运维人员哪些参数可以被覆盖掉,我们这里的意思就是默认值为 db,当然也可以被运维来覆盖掉这个值.
现在我们需要的两个组件定义完成后,就可以来定义配置和特征了。如下资源清单是我们这里声明的一个应用配置:(configuration.yaml)
apiVersion: core.oam.dev/v1alpha1
kind: ApplicationConfiguration
metadata:
name: todo-app
spec:
components:
- componentName: backend
instanceName: mongo
- componentName: frontend
instanceName: fe
parameterValues:
- name: database
value: mongo
traits:
- name: ingress
parameterValues:
- name: hostname
value: todo.qikqiak.com
- name: service_port
value: 3000
- name: path
value: /
这个配置资源清单我们做了两件事情,为每个组件定义一个实例名称以及 Web 应用程序需要的环境变量,比如我们这里定义了 backend 的组件实例 mongo,frontend 组件的实例 fe,并且还用 backend 的实例名来覆盖 database 这个参数,也就是 Web 应用程序中对应的 DB 这个环境变量。后面我们还配置了一个 Ingress 特征入口,其实就是定义 Ingress 对象的一些字段。
然后接下来我们就可以部署组件、配置和特征了。首先创建组件:
➜ oam kubectl apply -f components.yaml
componentschematic.core.oam.dev/backend created
componentschematic.core.oam.dev/frontend created
创建组件并不会创建 Kubernetes Pods 对象,只有在部署了与组件相关的 Rudr 配置后才会部署:
➜ oam kubectl apply -f ApplicationConfiguration.yaml
applicationconfiguration.core.oam.dev/todo-app created
价值
通过上面的介绍,我们了解了 OAM Spec 里面的基本概念和定义,以及如何使用它们来描述应用交付和运维流程。然而,OAM 能给我们带来什么样的价值呢?
我们评判一个好的架构体系,不仅是因为它在技术上更先进,更主要的是它能够解决一些实际问题,为用户带来价值。所以,接下来我们将总结一下这方面的内容。
OAM 的价值要从下往上三个层面来说起。
- 从基础设施层面
基础设施,指的是像 K8s 这类的提供基础服务能力与抽象的一层服务体系。拿 K8s 来说,它提供了许多种类的基础服务和强大的扩展能力来灵活扩展其他基础服务。
但是,使用基础设施的运维人员很快就发现 K8s 存在一个问题:缺乏统一的机制来注册和管理自定义扩展能力。这些扩展能力的表达方式不够统一,有些是 CRD、有些是 annotation、有些是 Config…
这种乱象使得基础设施用户不知道平台上都提供了哪些能力,不知道怎么使用这些能力,更不知道这些能力互相之间的兼容组合关系。
OAM 提供了抽象(如 Workload/Trait 等)来统一定义和管理这些能力。有了 OAM,各平台实现就有了统一的标准规范去透出公共的或差异化的能力:公共的基础服务像容器部署、监控、日志、灰度发布;差异化的、高级复杂的能力像 CronHPA(周期性定时变化的强化版 HPA)。
- 从应用运维者层面
应用运维,指的是像给应用加上网络接入、复杂均衡、弹性伸缩、甚至是建站等运维操作。但是,运维的一个痛点就是原来这些能力并不是跨平台的:这导致在不同平台、不同环境下去部署和运维应用的操作,是不互通和不兼容的。
上面这个问题,是客户应用、尤其是传统 ERP 应用上云的一大阻碍。我们做 OAM 的一个初衷,就是通过一套标准定义,让不同的平台实现也通过统一的方式透出。我们希望:哪怕一个应用不是生在云上、长在云上,也能够赶上这趟通往云原生未来的列车,拥抱云带来的变化和红利
OAM 提供的抽象和模型,是我们通往统一、标准的应用架构的强有力工具。这些标准能力以后都会通过 OAM 输出,让运维人员轻易去实现跨平台部署。
- 从应用开发者层面
应用开发,指的就是业务逻辑开发,这是业务产生价值的核心位置。
也正因如此,我们希望,应用开发者能够专注于业务开发,而不需要关心运维细节。但是,K8s 提供的 API,并没有很好地分离开发和运维的关注点,开发和运维之间需要来回沟通以避免产生误解和冲突。
OAM 分离了开发和运维的关注点,很好地解决了以上问题,让整个发布流程更加连贯、高效。
「真诚赞赏,手留余香」
 Richie Time
Richie Time
真诚赞赏,手留余香
使用微信扫描二维码完成支付
